Robots and Physical Intuition
Learning Physical Intuition for Robotic Manipulation
 Oliver Groth
Oliver Groth
Thesis for Doctor of Philosophy, December 2021
Abstract
When we compare object manipulation capabilities in humans and contemporary robots, we observe an intriguing dichotomy: On one hand, robots have access to advanced compute capacity and precise models of physics, yet their object manipulation skills are comparatively narrow and brittle. On the other hand, the human understanding of physics is allegedly acquired from experience and exhibits many predictive shortcomings, yet their manipulation skills far exceed any contemporary robot's. Motivated by this observation, this thesis studies the question how much robotic manipulation can benefit from embracing data-driven, approximate models of physics and poses the hypothesis that a tight integration of intuition and control can unlock sophisticated manipulation behaviour.In particular, three aspects of physical intuition are investigated: (i) high-level intuitions for visual task assessment and their application in object stacking and tool use, (ii) low-level intuitions for rigid-body motions and their application in rearrangement planning and visuomotor control, (iii) the integration of dynamics approximation into control policy learning and its application in structured exploration of an environment.
In the first part, we demonstrate the effectiveness of a visual stability classifier in planning and constructing stable stacks of objects with varying geometries. We also employ a similar task classification technique in a goal-reaching task and show that the associated variational latent space induces an affordance manifold which can be traversed to synthesise suitable tools for a given task. In the second part, we demonstrate that the introduction of dynamics modelling into an object-centric latent space facilitates object disentanglement from raw visual training data and allows to generate physically plausible scenes and videos from scratch. Visual dynamics approximation is also used in our novel, goal-conditioned, visuomotor control architecture where it enables zero-shot transfer to unseen object rearrangement tasks. Finally, we integrate dynamics forecasting and control policy learning in the third part of this thesis and optimise both components using a curiosity objective. This setup leads to the unsupervised emergence of complex, human interpretable manipulation and locomotion behaviour and highlights the crucial importance of physical intuition in the learning process of sophisticated, embodied behaviour.
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
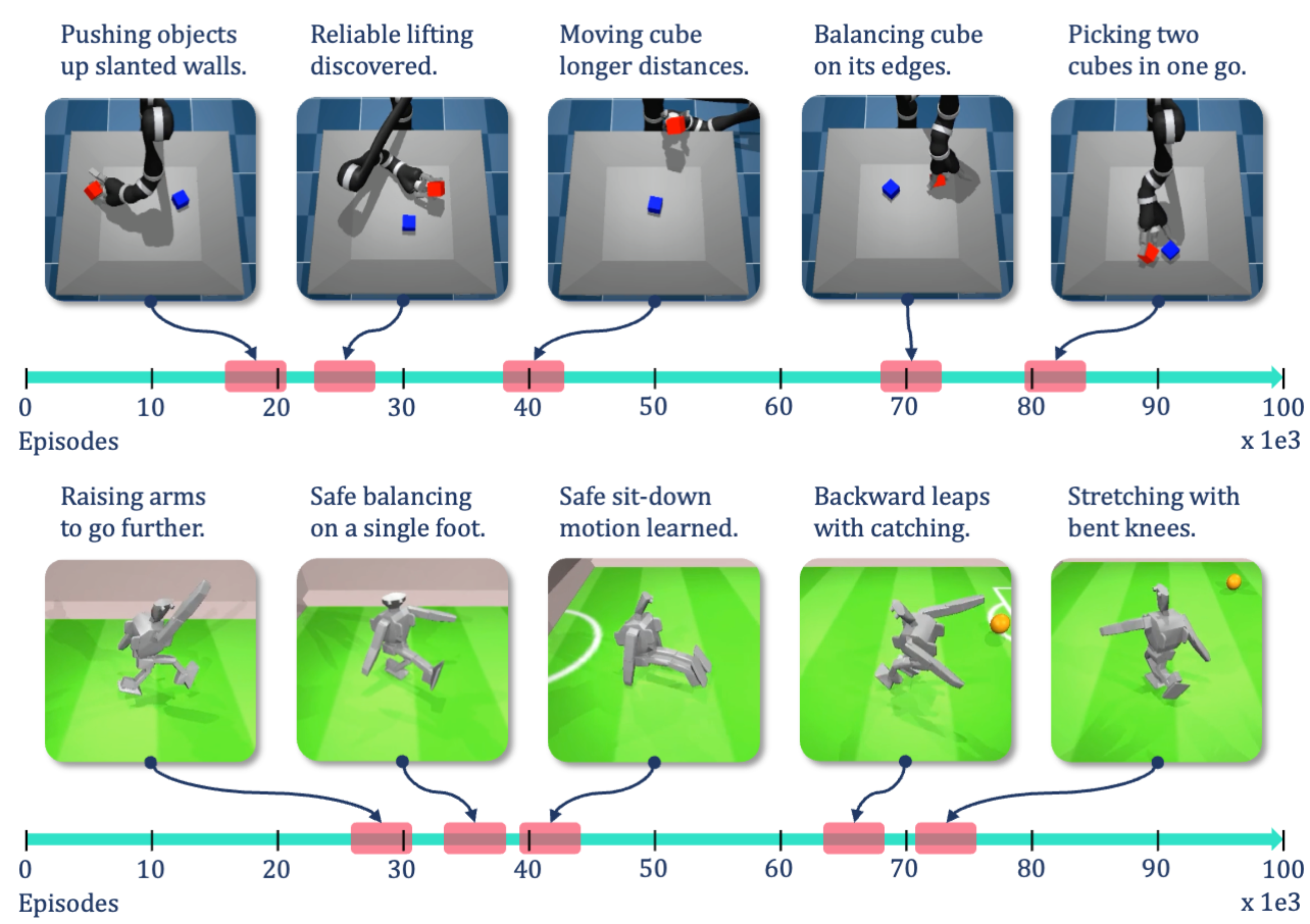 Oliver Groth, Markus Wulfmeier, Giulia Vezzani, Vibhavari Dasagi, Tim Hertweck, Roland Hafner, Nicolas Heess, Martin Riedmiller
Oliver Groth, Markus Wulfmeier, Giulia Vezzani, Vibhavari Dasagi, Tim Hertweck, Roland Hafner, Nicolas Heess, Martin Riedmiller
arXiv preprint, September 2021
Abstract
Curiosity-based reward schemes can present powerful exploration mechanisms which facilitate the discovery of solutions for complex, sparse or long-horizon tasks. However, as the agent learns to reach previously unexplored spaces and the objective adapts to reward new areas, many behaviours emerge only to disappear due to being overwritten by the constantly shifting objective. We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent's repertoire to solve related tasks. Our experiments demonstrate the continuous shift in behaviour throughout training and the benefits of a simple policy snapshot method to reuse discovered behaviour for transfer tasks.Goal-Conditioned End-to-End Visuomotor Control for Versatile Skill Primitives
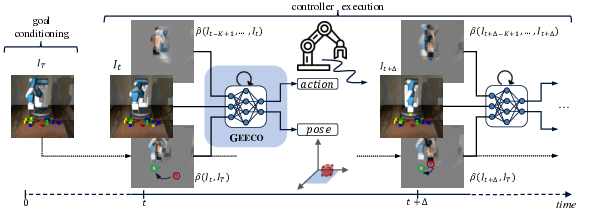 Oliver Groth, Chia-Man Hung, Andrea Vedaldi, Ingmar Posner
Oliver Groth, Chia-Man Hung, Andrea Vedaldi, Ingmar Posner
ICRA 2021
[paper] [bibtex] [code] [video]
Abstract
Visuomotor control (VMC) is an effective means of achieving basic manipulation tasks such as pushing or pick-and-place from raw images. Conditioning VMC on desired goal states is a promising way of achieving versatile skill primitives. However, common conditioning schemes either rely on task-specific fine tuning - e.g. using one-shot imitation learning (IL) - or on sampling approaches using a forward model of scene dynamics i.e. model-predictive control (MPC), leaving deployability and planning horizon severely limited. In this paper we propose a conditioning scheme which avoids these pitfalls by learning the controller and its conditioning in an end-to-end manner. Our model predicts complex action sequences based directly on a dynamic image representation of the robot motion and the distance to a given target observation. In contrast to related works, this enables our approach to efficiently perform complex manipulation tasks from raw image observations without predefined control primitives or test time demonstrations. We report significant improvements in task success over representative MPC and IL baselines. We also demonstrate our model's generalisation capabilities in challenging, unseen tasks featuring visual noise, cluttered scenes and unseen object geometries.RELATE: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces
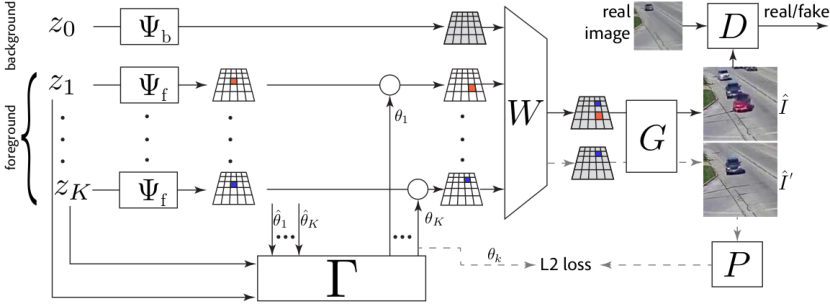 Sébastien Ehrhardt *, Oliver Groth *, Aron Monszpart, Martin Engelcke, Ingmar Posner, Niloy Mitra, Andrea Vedaldi
Sébastien Ehrhardt *, Oliver Groth *, Aron Monszpart, Martin Engelcke, Ingmar Posner, Niloy Mitra, Andrea Vedaldi
NeurIPS 2020
[paper] [bibtex] [code] [page] [video] [poster]
Abstract
We present RELATE, a model that learns to generate physically plausible scenes and videos of multiple interacting objects. Similar to other generative approaches, RELATE is trained end-to-end on raw, unlabeled data. RELATE combines an object-centric GAN formulation with a model that explicitly accounts for correlations between individual objects. This allows the model to generate realistic scenes and videos from a physically-interpretable parameterization. Furthermore, we show that modeling the object correlation is necessary to learn to disentangle object positions and identity. We find that RELATE is also amenable to physically realistic scene editing and that it significantly outperforms prior art in object-centric scene generation in both synthetic (CLEVR, ShapeStacks) and real-world data (cars). In addition, in contrast to state-of-the-art methods in object-centric generative modeling, RELATE also extends naturally to dynamic scenes and generates videos of high visual fidelity.Learning Affordances in Object-Centric Generative Models
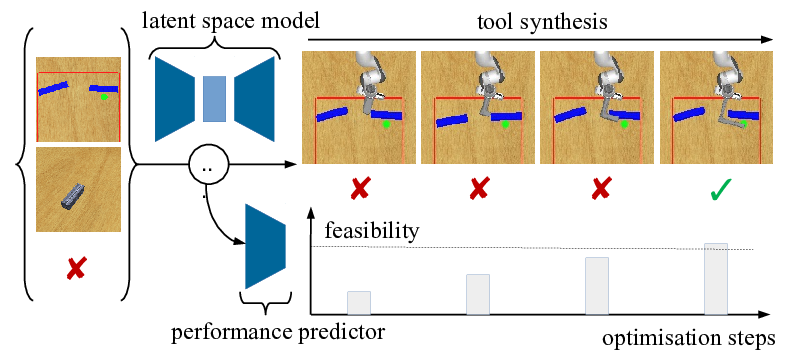 Yizhe Wu *, Sudhanshu Kasewa *, Oliver Groth *, Sasha Salter, Li Sun, Oiwi Parker Jones, Ingmar Posner
Yizhe Wu *, Sudhanshu Kasewa *, Oliver Groth *, Sasha Salter, Li Sun, Oiwi Parker Jones, Ingmar Posner
Workshop on Object-Oriented Learning (OOL) at ICML 2020
Outstanding Paper Award
Abstract
Given visual observations of a reaching task together with a stick-like tool, we propose a novel approach that learns to exploit task-relevant object affordances by combining generative modelling with a task-based performance predictor. The embedding learned by the generative model captures the factors of variation in object geometry, e.g. length, width, and configuration. The performance predictor identifies sub-manifolds correlated with task success in a weakly supervised manner. Using a 3D simulation environment, we demonstrate that traversing the latent space in this task-driven way results in appropriate tool geometries for the task at hand. Our results suggest that affordances are encoded along smooth trajectories in the learned latent space. Given only high-level performance criteria (such as task success), accessing these emergent affordances via gradient descent enables the agent to manipulate learned object geometries in a targeted and deliberate way.Scrutinizing and De-Biasing Intuitive Physics with Neural Stethoscopes
 Fabian B Fuchs, Oliver Groth, Adam R Kosiorek, Alex Bewley, Markus Wulfmeier, Andrea Vedaldi, Ingmar Posner
Fabian B Fuchs, Oliver Groth, Adam R Kosiorek, Alex Bewley, Markus Wulfmeier, Andrea Vedaldi, Ingmar Posner
BMVC 2019
[paper] [bibtex] [page] [poster]
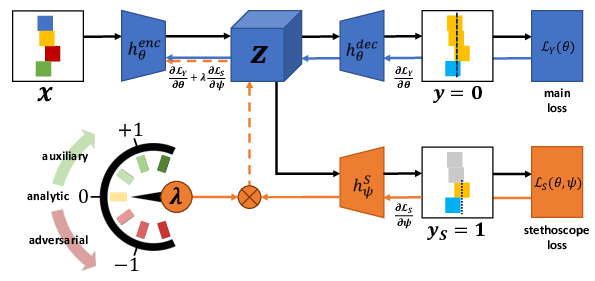
Abstract
Visually predicting the stability of block towers is a popular task in the domain of intuitive physics. While previous work focusses on prediction accuracy, a one-dimensional performance measure, we provide a broader analysis of the learned physical understanding of the final model and how the learning process can be guided. To this end, we introduce neural stethoscopes as a general purpose framework for quantifying the degree of importance of specific factors of influence in deep neural networks as well as for actively promoting and suppressing information as appropriate. In doing so, we unify concepts from multitask learning as well as training with auxiliary and adversarial losses. We apply neural stethoscopes to analyse the state-of-the-art neural network for stability prediction. We show that the baseline model is susceptible to being misled by incorrect visual cues. This leads to a performance breakdown to the level of random guessing when training on scenarios where visual cues are inversely correlated with stability. Using stethoscopes to promote meaningful feature extraction increases performance from 51% to 90% prediction accuracy. Conversely, training on an easy dataset where visual cues are positively correlated with stability, the baseline model learns a bias leading to poor performance on a harder dataset. Using an adversarial stethoscope, the network is successfully de-biased, leading to a performance increase from 66% to 88%.Shapestacks: Learning Vision-based Physical Intuition for Generalised Object Stacking
 Oliver Groth, Fabian B Fuchs, Ingmar Posner, Andrea Vedaldi
Oliver Groth, Fabian B Fuchs, Ingmar Posner, Andrea Vedaldi
ECCV 2018
[paper] [bibtex] [code] [blog] [page] [video] [poster]
Abstract
Physical intuition is pivotal for intelligent agents to perform complex tasks. In this paper we investigate the passive acquisition of an intuitive understanding of physical principles as well as the active utilisation of this intuition in the context of generalised object stacking. To this end, we provide ShapeStacks: a simulation-based dataset featuring 20,000 stack configurations composed of a variety of elementary geometric primitives richly annotated regarding semantics and structural stability. We train visual classifiers for binary stability prediction on the ShapeStacks data and scrutinise their learned physical intuition. Due to the richness of the training data our approach also generalises favourably to real-world scenarios achieving state-of-the-art stability prediction on a publicly available benchmark of block towers. We then leverage the physical intuition learned by our model to actively construct stable stacks and observe the emergence of an intuitive notion of stackability-an inherent object affordance-induced by the active stacking task. Our approach performs well exceeding the stack height observed during training and even manages to counterbalance initially unstable structures.Image Captioning
Visual Genome: Connecting Language and Vision using Crowdsourced Dense Image Annotations
 Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael S Bernstein, Fei-Fei Li
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael S Bernstein, Fei-Fei Li
IJCV 2017
[paper] [bibtex] [code] [page] [media]
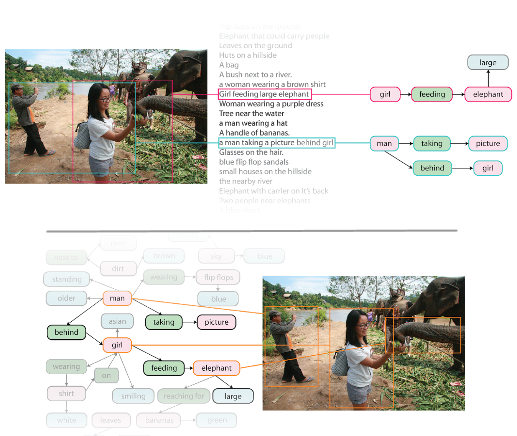
Abstract
Despite progress in perceptual tasks such as image classification, computers still perform poorly on cognitive tasks such as image description and question answering. Cognition is core to tasks that involve not just recognizing, but reasoning about our visual world. However, models used to tackle the rich content in images for cognitive tasks are still being trained using the same datasets designed for perceptual tasks. To achieve success at cognitive tasks, models need to understand the interactions and relationships between objects in an image. When asked “What vehicle is the person riding?”, computers will need to identify the objects in an image as well as the relationships riding(man, carriage) and pulling(horse, carriage) to answer correctly that “the person is riding a horse-drawn carriage.” In this paper, we present the Visual Genome dataset to enable the modeling of such relationships. We collect dense annotations of objects, attributes, and relationships within each image to learn these models. Specifically, our dataset contains over 108K images where each image has an average of 35 objects, 26 attributes, and 21 pairwise relationships between objects. We canonicalize the objects, attributes, relationships, and noun phrases in region descriptions and questions answer pairs to WordNet synsets. Together, these annotations represent the densest and largest dataset of image descriptions, objects, attributes, relationships, and question answer pairs.Visual7W: Grounded Question Answering in Images
 Yuke Zhu, Oliver Groth, Michael Bernstein, Li Fei-Fei
Yuke Zhu, Oliver Groth, Michael Bernstein, Li Fei-Fei
CVPR 2016
[paper] [bibtex] [code] [page] [poster]
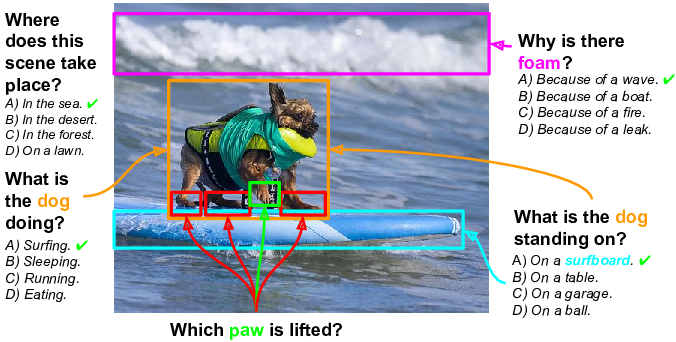
Abstract
We have seen great progress in basic perceptual tasks such as object recognition and detection. However, AI models still fail to match humans in high-level vision tasks due to the lack of capacities for deeper reasoning. Recently the new task of visual question answering (QA) has been proposed to evaluate a model's capacity for deep image understanding. Previous works have established a loose, global association between QA sentences and images. However, many questions and answers, in practice, relate to local regions in the images. We establish a semantic link between textual descriptions and image regions by object-level grounding. It enables a new type of QA with visual answers, in addition to textual answers used in previous work. We study the visual QA tasks in a grounded setting with a large collection of 7W multiple-choice QA pairs. Furthermore, we evaluate human performance and several baseline models on the QA tasks. Finally, we propose a novel LSTM model with spatial attention to tackle the 7W QA tasks.Semantic Segmentation and Depth Prediction
Analyzing Modular CNN Architectures for Joint Depth Prediction and Semantic Segmentation
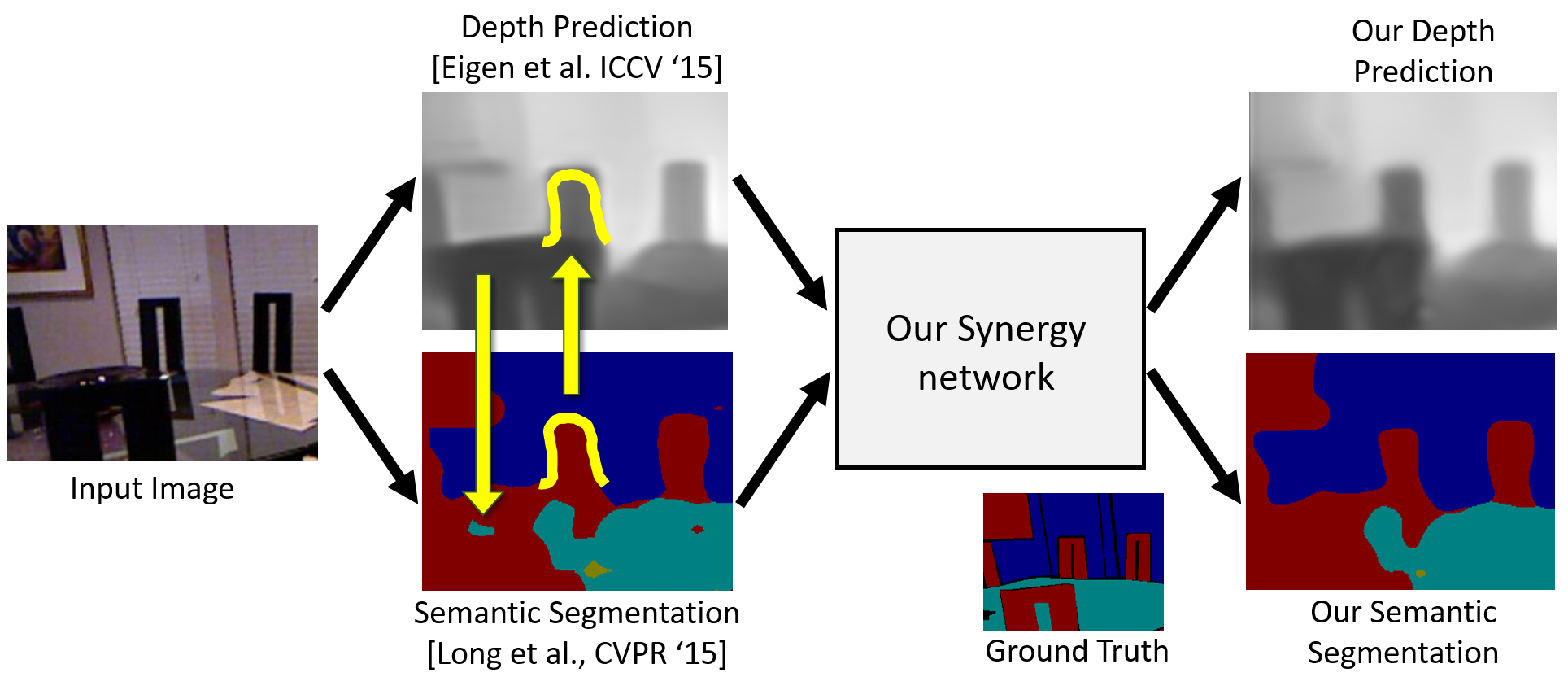 Omid Hosseini Jafari, Oliver Groth, Alexander Kirillov, Michael Ying Yang, Carsten Rother
Omid Hosseini Jafari, Oliver Groth, Alexander Kirillov, Michael Ying Yang, Carsten Rother
ICRA 2017